
简介
这篇文章介绍了一整套Benchmark,用来研究大规模微服务架构是怎么影响系统表现的,以及这种架构与过去的传统架构在负载水平和资源水平发生变化时会有什么样的不同。总的来说,作者的观点包括如下内容:
- 微服务对于延迟控制会提出更高的要求
- 微服务架构会在时间上支出更多的网络开销
- 由于微服务之间的关联性,微服务架构对集群管理的要求更高,问题会在微服务之间级联扩散
- 传统的自动伸缩方案在面对微服务的关联性时不完全适用
- 尾延迟问题在微服务架构中会更明显,链路中的局部环节对全链路都会产生影响
DeathStarBench
之所以叫这个名字是因为大型系统中微服务之间的关联会让连接图看起来就像一个死亡星球一样。

设计原则
为了让这个benchmark能更好的反应真实情况,作者遵照如下的设计原则:
具有代表性
作者尽可能的使用最流行的组件来完成系统的搭建,比如Nginx,Memcached,MongoDB等等,通信采用常用的通信方案,比如Thrift,gRPC等。
端到端操作
为了研究整个系统内微服务之间的关联会对系统表现造成什么影响,这个benchmark实现了整个服务链路而不是路径上的某些组件,也就是说从请求产生一直到请求被后端处理后再返回的整个路径都在观测范围内。
异构性
微服务架构通常内部会包含各种各样的语言,子架构等等,Benchmark的设计也遵照了这一点。在约定的通信机制下,不同的微服务采用了不同的实现方式。
模块化
作者遵照了康威定律,对服务进行了尽可能的拆分和模块化,避免相关联的微服务之间过多的双向通信,确保模块都是单一专注以及松耦合的。
可重配置
整个Benchmark的所有组件都是可以重新配置的。符合微服务结构灵活的特性。
构成部分
整个Benchmark由多个功能不同,结构不同甚至架构不同的微服务构成。
- Social Network Service
- Media Service
- E-commerce Service
- Banking System

- Swarm Service
这个无人机控制服务是最特殊的一个,他涉及到了端云协同。这里作者做了两个方案,一个是把重计算放在云上,一个是把重计算放在无人机上(运动控制,图像识别,避障,图像数据库)

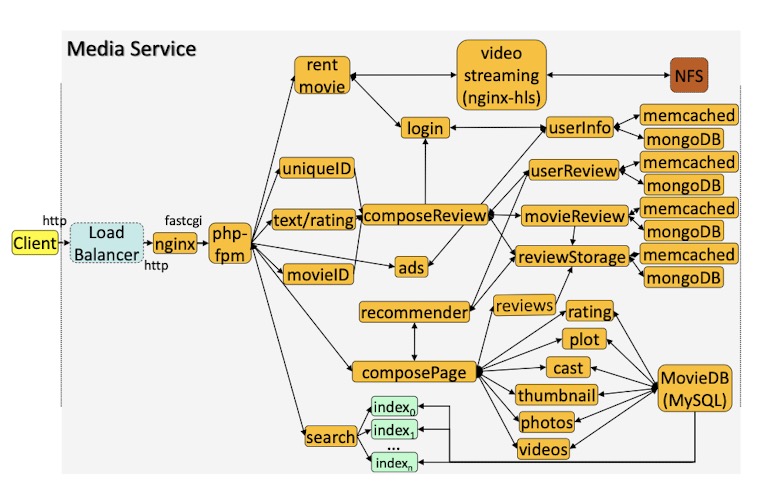
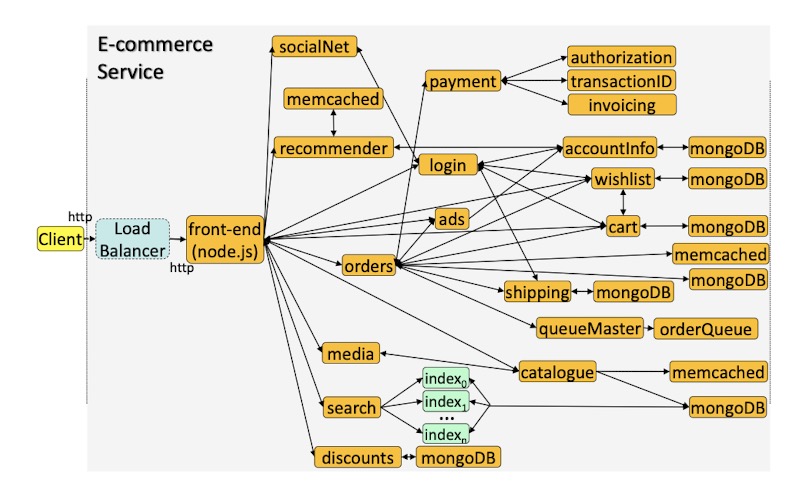
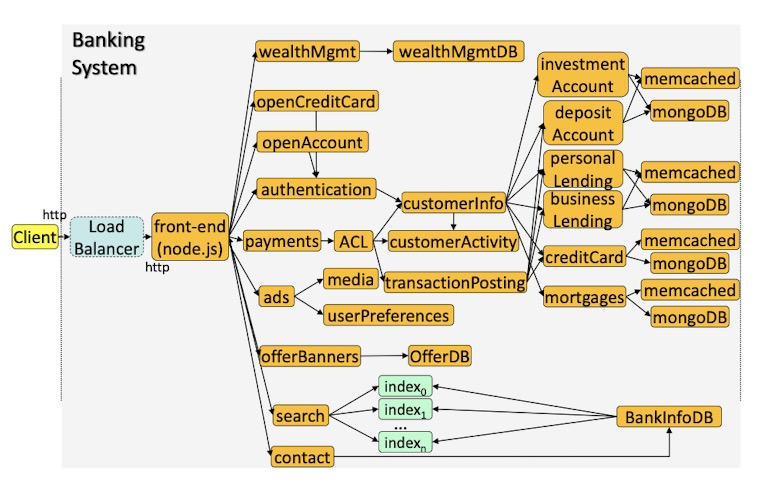
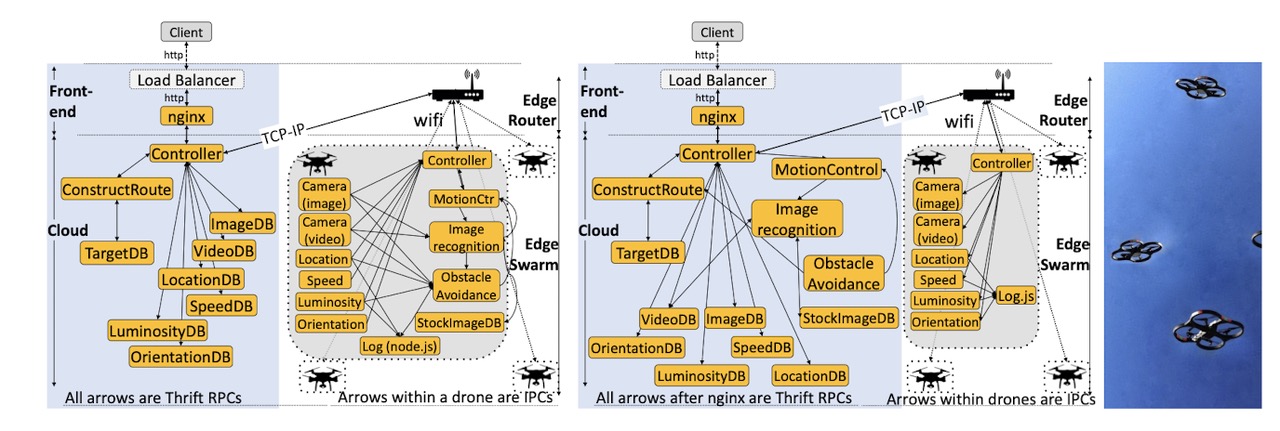
Methodological Challenges of Microservices
为了精确的得到整个集群的状态报告,作者们还自己做了一套全链路的分布式性能追踪系统,记录了系统各个环节上尾延迟以及进程执行耗时的情况。这套系统本身很轻,对系统的影响不大,不影响统计结果。
Provisioning & Query Diversity
为了不让某些环节过早的引入性能瓶颈,作者们对资源的分配尽可能公平,确保所有环节在大致相同的负载下达到饱和。不同环节对资源的要求情况差别很大,这体现了微服务架构中的应用感知资源管理需求。不同的查询方式对性能也会有很大的影响。在IoT的场景下,端云之间不同的资源分配情况也会对性能产生很大影响,由于无人机必须在数十米的距离上与无线路由器进行通信,因此延迟要比纯云服务高得多。当在云中进行处理时,低负载时的延迟会更高,这会受到较长的网络延迟的影响。但是,随着负载的增加,由于板载资源有限,边缘设备很快变得捉襟见肘。对于相同的尾部延迟,云上的处理可实现7.8倍的高吞吐量,而对于相同的吞吐量,则可将延迟降低20倍。
Architectural Implications
所有的微服务性能都会受到请求量和硬件性能变化的影响。其中,请求量变化的影响要高于集群性能的变化影响。
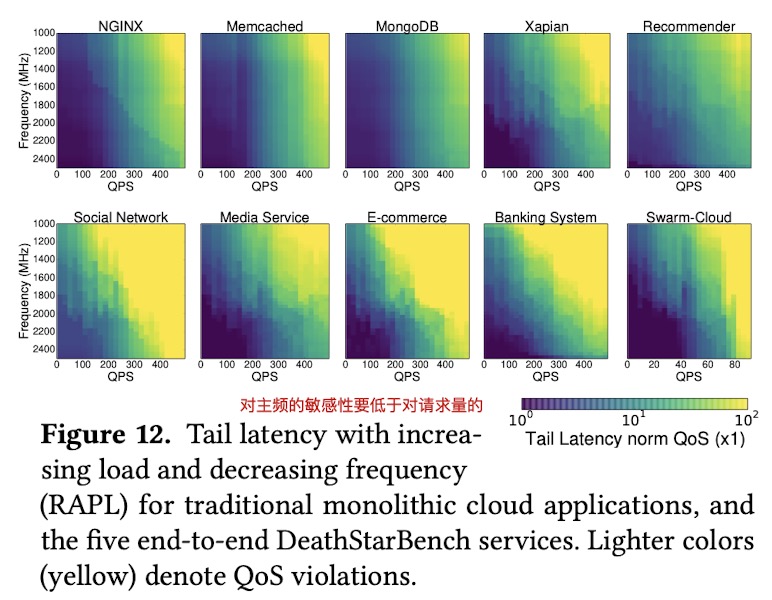
 微服务架构比传统的单例应用体系对集群硬件性能的变化更加敏感。但是如果服务本身是I-O Bound或者类似Swarm那样是Network Bound的话,那么对性能变化会没有那么敏感。
微服务架构比传统的单例应用体系对集群硬件性能的变化更加敏感。但是如果服务本身是I-O Bound或者类似Swarm那样是Network Bound的话,那么对性能变化会没有那么敏感。
OS & Networking Implications
首先是在系统内核态和用户态切换上,微服务架构因为其频繁的用于处理TCP包等的系统中断,和对外部库的调用(便于开发),导致其大量的CPU时间处于内核态。
在不同的负载情况下,业务计算和网络计算所占用的时间比例会发生显著的变化。低负载下,网络处理占用的时间是较低的,而在高负载下,对于所有端到端服务(除了电子商务和银行业务)而言,网络处理成为尾部延迟的一个更为明显的因素,因为网卡中会排起长队。但传统的单例应用无论在哪种负载下,网络部分的开销占比都不大。在网络条件得到优化之后,微服务架构内的尾延迟现象会得到非常明显的改善。

Cluster Management Implications
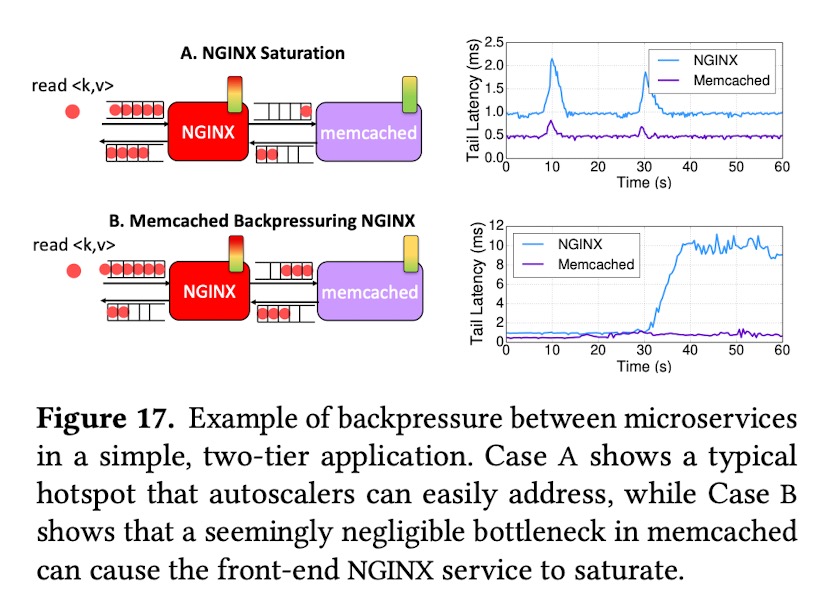
微服务架构会让集群管理变得更加复杂。通常,自动伸缩机制会在业务饱和时进行扩容,在微服务架构下,这种做法可能会导致情况更坏。作者举了一个Nginx和Memcached组合的例子。在普通情况下,Nginx首先达到饱和状态,系统自动伸缩了Nginx,很容易就消除了峰。但是在另一种情况下,在使用HTTP/1时,Memcached处理请求是阻塞式的单线执行的,使得Nginx必须等待Memcached执行完毕。在系统监控看来,Memcached按照正常的速度处理请求,并没有饱和,而Nginx这时候出现了大量的latency。但是,如果此时扩容Nginx,只会导致情况更加糟糕。这种情况叫Backpressure。在真实的场景下,情况只会更加复杂。
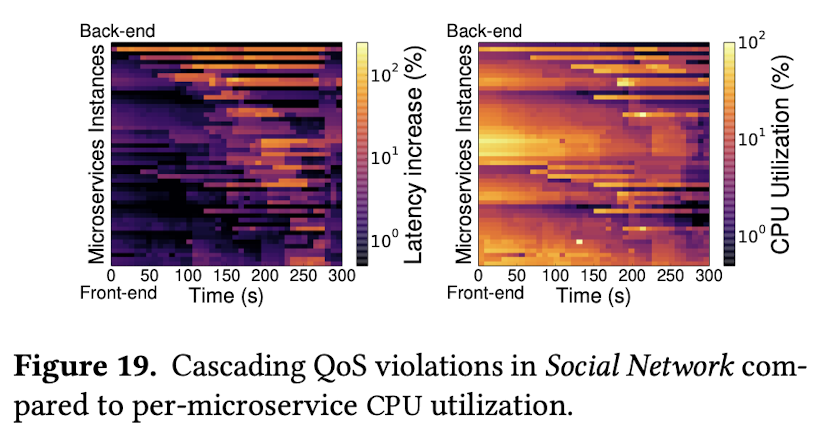
 作者们观察到,在微服务架构下,QoS故障级联扩散的特性。通过对业务热力图的观察,一旦后端服务出现了高延迟,就会传播到其上游服务,并一直传播到前端。 在这种情况下,对CPU利用率的观察可能会产生误导。 中游的一些业务可能有更高的CPU利用率,但是没有出现Latency。
作者们观察到,在微服务架构下,QoS故障级联扩散的特性。通过对业务热力图的观察,一旦后端服务出现了高延迟,就会传播到其上游服务,并一直传播到前端。 在这种情况下,对CPU利用率的观察可能会产生误导。 中游的一些业务可能有更高的CPU利用率,但是没有出现Latency。
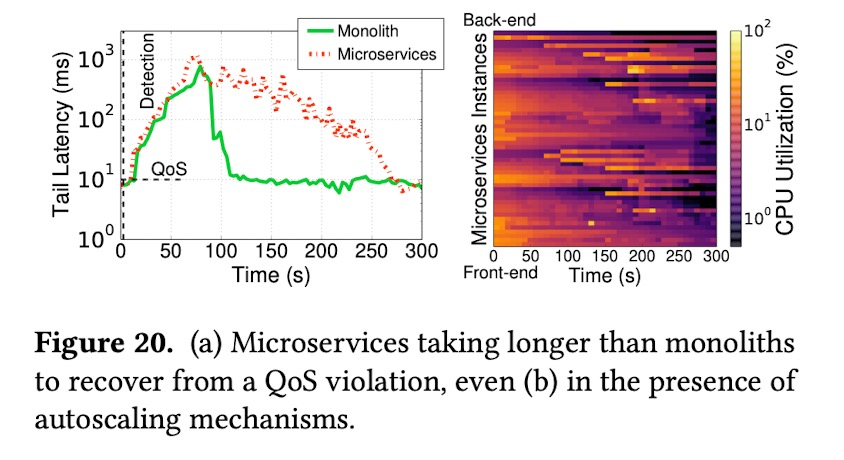
 这些复杂的特性,会让集群比传统的云架构更难以从故障中恢复,即使有自动伸缩机制。单体应用可以快速的通过伸缩单例来让集群恢复正常,而微服务架构需要更久的时间定位问题并恢复。因为朴素的扩容机制可能会直接把CPU利用率高的那些微服务进行扩展,但是他们可能并不是造成系统延迟的罪魁祸首(延迟可能是上游传递下来的)。
这些复杂的特性,会让集群比传统的云架构更难以从故障中恢复,即使有自动伸缩机制。单体应用可以快速的通过伸缩单例来让集群恢复正常,而微服务架构需要更久的时间定位问题并恢复。因为朴素的扩容机制可能会直接把CPU利用率高的那些微服务进行扩展,但是他们可能并不是造成系统延迟的罪魁祸首(延迟可能是上游传递下来的)。
Application & Programming Framework Implications
作者们对延迟的主要来源在不同的负载水平下做了拆解。在低负载情况下,延迟主要来自于前端部分(Nginx),MongoDB例外,贡献了10%左右的延迟。但是在高负载情况下,延迟的主要来源就开始后移到后端数据库以及相关的数据服务上。这表明,微服务架构下,性能的瓶颈会随负载变化而变化,这给动态和敏捷管理带来了更大的压力。
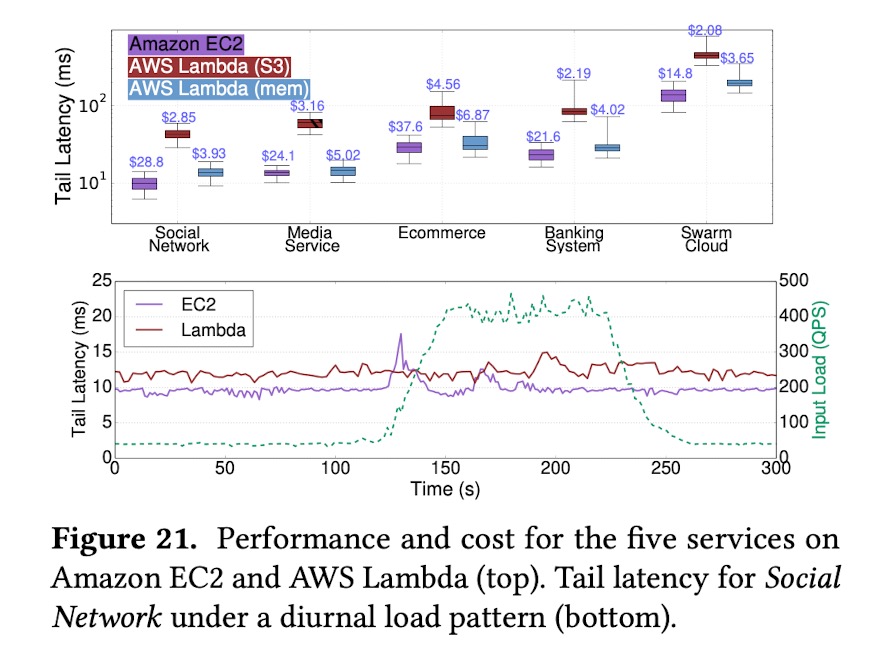
不同的基础架构也会对性能产生影响。作者们分别在三种基础设施上部署了整套业务,Amazon EC2服务器、使用S3持久化存储中间结果的AWS的函数计算,以及使用额外的内存服务器来存储中间结果的AWS函数计算。由于引入了额外的存储环节,AWS(S3)的整体延迟是很高的,即使传输的数据量很小,使用内存存储会改善这个现象。但是,函数计算的延迟表现依然不稳定。因为函数可能会被部署在数据中心集群的不同位置。不过,Lambda在处理业务量的快速变化时,表现要比EC2方案好,因为其伸缩更快
Tail at scale implications
作者用真实的业务数据来研究微服务架构下的tail at scale效应。首先能从社交应用中,观察到大规模的级联扩散效应。其次,在面向用户的云服务中,负载很少是均匀的,有些少量的用户会生成大量的负载。 社交网络中的实际流量通常遵循此原则,5%的用户产生了超过30%的请求。 为了将请求偏斜研究到极致,作者们额外注入了合成用户,该用户生成的请求数量比典型用户大得多。结果发现,当这种不平衡的请求量增长时,整体的QoS会迅速下降。最后,作者们研究了集群中性能较差的机器会产生什么影响。对于大型集群(> 100个实例),当1%或更多的服务器表现不佳时,吞吐量几乎为零,因为这些服务器在关键路径上托管至少一个微服务,从而降低了QoS。 对于小型集群(40个实例),单个慢速服务器是服务可以继续维持的最大数量,并且在QoS下仍可以实现一些QPS。而单体应用架构并不显著受慢服务器的影响,除非是后端共享的数据库部分受到了影响。通常,应用程序的微服务关联关系越复杂,慢速服务器的影响就越大,关键路径上的服务将被降级的可能性增加。

相关评论