
从Linux网络模型开始讲Kubernetes的网络通信原理,本节讲Linux网络命名空间、Docker网络模型以及Flannel通信原理。
对于一个刚接触Kubernetes的新手来说,可能最费解的地方就是,为什么Kubernetes提供了那么多强大的功能,唯独不提供网络支持,而是让用户自己去指定网络实现。实际上,不同公司对于网络模型有不同的设计想法。网络,尤其是ip地址的规划,一定程度上体现了公司基础设施的规划方式。比如有些公司会指定某个子网下的所有终端(服务器、NAS设备等)用于提供数据服务,这些终端设备往往也在地理上邻近。一种很常见的做法是,把不同的DC通过网段区分开。因此,可以认为网络的规划是一种业务的体现,而基础设施是服务于业务的,因此将与业务深度绑定的网络构建工作完全交给用户是一种合理的做法。
Kubernetes对网络的唯一要求就是所有的Pod之间必须直接可达。当我们聊CNI怎么构建网络的时候,是不需要考虑Kubernetes的。Kubernetes等用户把网络模型构建完成后才入场构建更上层的建筑,创建新容器时,利用/opt/cni/bin下的可执行文件为容器分配网络,构建逻辑依然是由CNI本身决定的。
Linux命名空间
容器技术所提供的隔离性来自于Linux Namespace和CGroups。前者提供了隔离性,后者提供了资源的分配与限额。本文内容只涉及到Namespace中网络的部分。Linux一共提供了六种命名空间来实现不同的隔离需求。
| 命名空间 | 描述 | 作用 | 备注 |
|---|---|---|---|
| 进程命名空间 | 隔离进程ID | Linux通过命名空间管理进程号,同一个进程,在不同的命名空间进程号不同 | 进程命名空间是一个父子结构,子空间对于父空间可见 |
| 网络命名空间 | 隔离网络设备、协议栈、端口等 | 通过网络命名空间,实现网络隔离 | docker采用虚拟网络设备,将不同命名空间的网络设备连接到一起 |
| IPC命名空间 | 隔离进程间通信 | 进程间交互方法 | PID命名空间和IPC命名空间可以组合起来用,同一个IPC名字空间内的进程可以彼此看见,允许进行交互,不同空间进程无法交互 |
| 挂载命名空间 | 隔离挂载点 | 隔离文件目录 | 进程运行时可以将挂载点与系统分离,使用这个功能时,我们可以达到 chroot 的功能,而在安全性方面比 chroot 更高 |
| UTS命名空间 | 隔离Hostname和NIS域名 | 让容器拥有独立的主机名和域名,从而让容器看起来像个独立的主机 | 主要目的是独立出主机名和网络信息服务(NIS) |
| 用户命名空间 | 隔离用户和group ID | 每个容器内上的用户跟宿主主机上不在一个命名空间 | 同进程 ID 一样,用户 ID 和组 ID 在命名空间内外是不一样的,并且在不同命名空间内可以存在相同的 ID |
在 Linux 中,网络名字空间可以被认为是隔离的拥有单独网络栈(网卡、路由转发表、iptables)的环境。网络名字空间经常用来隔离网络设备和服务,只有拥有同样网络名字空间的设备,才能看到彼此。从逻辑上说,网络命名空间是网络栈的副本,有自己的网络设备、路由选择表、邻接表、Netfilter表、网络套接字、网络procfs条目、网络sysfs条目和其他网络资源。从系统的角度来看,当通过clone()系统调用创建新进程时,传递标志CLONE_NEWNET将在新进程中创建一个全新的网络命名空间。[1]
容器的网络,实际上就是一个独立的网路命名空间。那么理论上,如果我们不做任何事,容器应该是完全独立的,宿主机感知不到其网络的存在。如果没有挂载宿主机的文件目录的话,我们甚至无法通过Unix Domain Socket与其中的进程通信。而且,这个命名空间中,并不存在任何真实的物理网卡,因此也不可能绕过宿主与外界通信。
为了让不同的网络命名空间能通信,Linux设计了Veth设备对。它成对出现,以网络设备的形式出现在命名空间中。我们可以理解为这是一条网线,把两个命名空间连起来。发往其中一个Veth设备的数据会被发送到另一个Veth上。这样,我们就能实现不同网络命名空间中的通信。对于容器网络,通常容器中的eth0网卡就是这样的一个设备对的一端。在初始化容器网络的时候,为命名空间内分配设备对的一端,为其分配ip,再为容器添加默认路由规则,最后在宿主机上通过添加NAT或者其他方式让容器能与外界通信。

Docker的网络模型
Docker提供了四种网络通信方式,分别是Host模式,网桥模式,Container模式,还有None模式。实际上,就是不同的分配网络空间的方式。None模式是只创建了一个命名空间,然后添加了一个回环网卡(lo),使其能ping通127.0.0.1这个地址,就是第一段提到的那种完全隔离的状态。Host模式则是不为容器创建新的命名空间,而是直接让容器与宿主机共享同一个命名空间。容器可以直接使用宿主机的网络设备进行通信。Container模式则是让新的容器共享一个既有容器的网络命名空间。就像Kubernetes中,一个Pod的不同Container之间可以直接使用127.0.0.1互相访问进程一样。
网桥模式是Docker默认提供的网络模式。Linux网桥是真实世界的交换机的一种虚拟实现,在系统中可以用于沟通多个不同的虚拟机网络和容器网络。注意,二者的连接方式通常不同,虚拟机下,主机eth0网卡会连接到网桥上,而Docker下,网桥和eth0网卡通过协议栈通信,这导致虚拟机的数据包通过网桥发往外网时,不需要做NAT,而容器的包需要做NAT,虚拟机的包不需要经过协议栈,而容器的包需要经过主机协议栈,也需要主机开启ip_forward功能,不然外界来的包会被直接丢掉,性能上会稍差一点。[2]
虚拟机和Docker的网桥连接方式的区别:
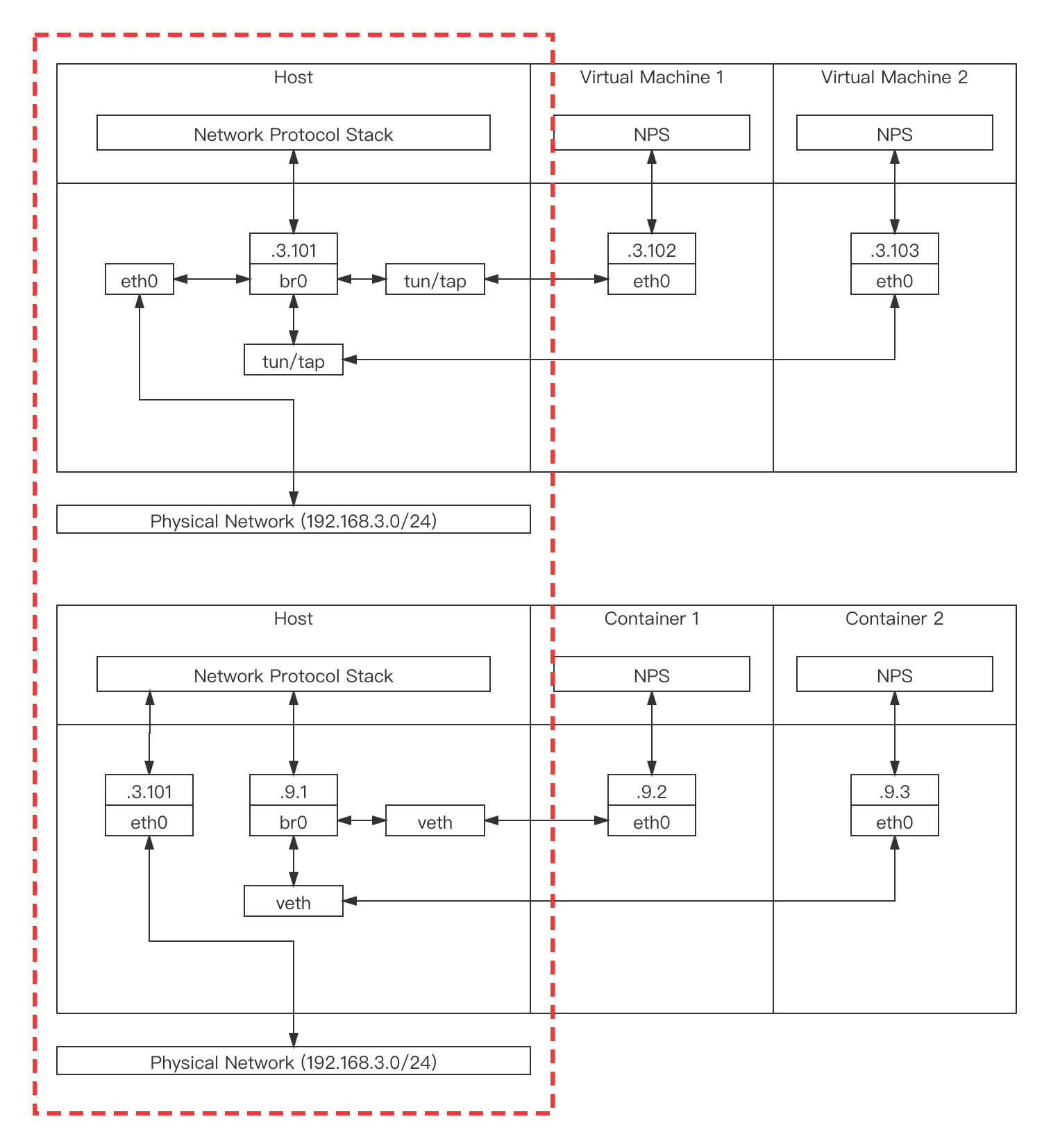
对网桥模型更进一步的解释可以参考[3]。
Docker网桥模式在单机内的Docker容器之间沟通时是可用的,而且性能不差,走的都是二层协议(可以从图中看到并不需要经过主机协议栈)。如果你的Kubernetes集群只有一个节点的话,那么其实这就已经可以用于构建单节点Kubernetes了。之所以有些同学使用kubeadm默认安装会失败,是因为没有配置好cidr地址池,需要把pod的cidr地址池与Docker的地址池配置成一样的。但是,对于多节点Kubernetes集群,这就不够用了。每个机器上的Docker0网桥是不互通的,pod的地址也会冲突。因此,就需要新的地址分配与通信策略,这些就是CNI要完成的工作。你可能会想,我把多个节点的Docker0网桥打平,让他们之间能互通,并且可以不冲突的分配地址不就好了。没错,这也是一种CNI的实现思路。我们来看看别人是怎么做的。
二层网络和三层网络
在正式介绍不同的CNI实现之前,需要先看一下,什么是二层网络,什么是三层网络。不同的CNI在大的拓扑上有不同的实现方式,像Flannel就是个二层方案,Calico是三层方案,Cilium可以做二层也可以做三层。
二层、三层是按照逻辑拓扑结构进行的分类,并不是说ISO七层模型中的数据链路层和网络层,而是指核心层,汇聚层和接入层,这三层都部署的就是三层网络结构,二层网络结构没有汇聚层。[4] 二层网络和三层网络一个明显的区别就是寻址方式的区别。二层网络没有IP地址和路由的概念,网络基于MAC地址寻址转发数据,数据以帧格式存在,不容易控制,存在广播风暴,一个二层网络是一个广播域一个冲突域。L2=物理层+数据链路层,属交换网络(MAC地址识别) 。L3包含了IP地址概念,可以路由,网络基于IP地址寻址转发,数据以包的形式存在,容易控制,隔离广播风暴,L3层网络的一个子网是一个广播域一个冲突域。[5]更多的细节内容可以看看引文的[4]和[6]。
Flannel
Flannel是一种基于二层Overlay网络的CNI实现方式。(什么是Overlay网络参见引文[7])简单来说就是,Flannel将不同主机之间的包通过其维护的二层隧道直接转发。Flannel解决了这样两个问题:
- 不同机器上Pod的网段划分的问题
- 不同机器上Pod的寻址和通信问题
它并没有在这之外做其他的工作,没有提供限流等等的功能。
Flannel is focused on networking. For network policy, other projects such as Calico can be used. Github: Flannel
下图是使用了VXLAN Backend的Flannel的结构图。
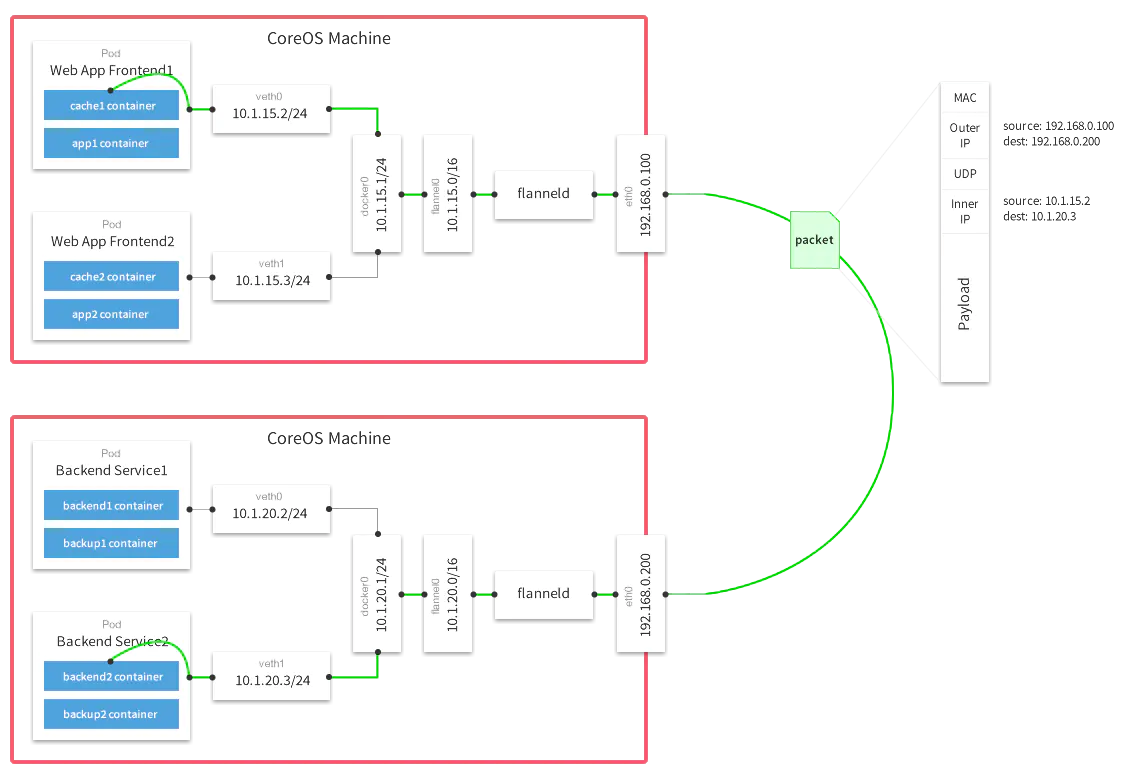
Flannel在节点上会安装两个设备,分别是cni0网桥设备和flanne1.1隧道设备。其中,cni0对应于图中的docker0。如果主机使用的容器引擎是Docker,那么主机上还会有一个Docker0网桥,他们的作用是一样的。Docker的网桥模式把容器的veth设备对的对端接在Docker0网桥上,Flannel把它接在cni0网桥上。之所以需要创建一个新的网桥,是因为一般默认的Docker0网桥与Flannel的默认地址池不一样。Flannel.1是一个隧道设备。当内核根据路由表将
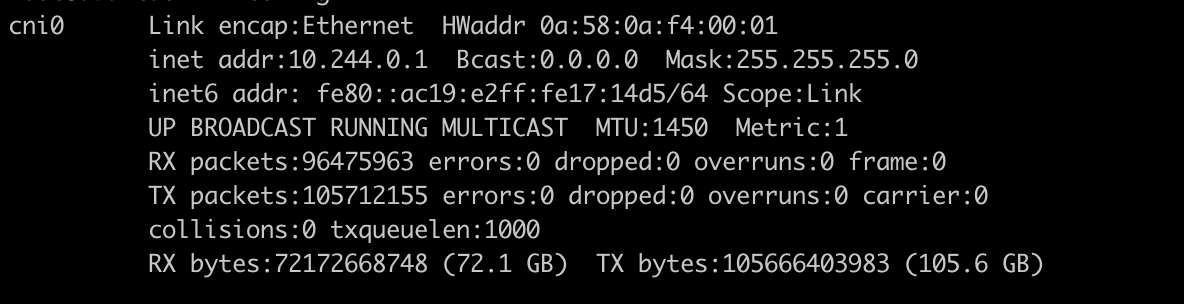
我们可以看一个实际部署了Flannel的机器上的路由表信息,本机容器在网段中被分配的地址是10.244.0.0/24,另外两个机器上10.244.1.0/24和10.244.2.0/24。主机的外网地址分别是192.168.111.25,192.168.111.26和192.168.111.27。
25机器上的网卡信息:
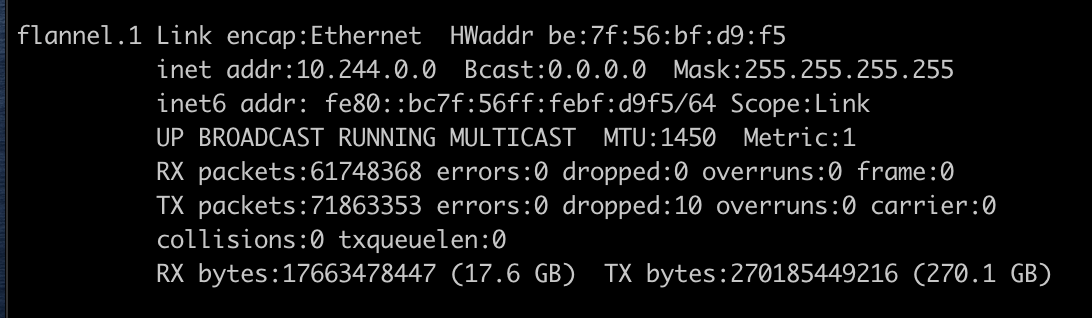
25机器上的路由表信息:
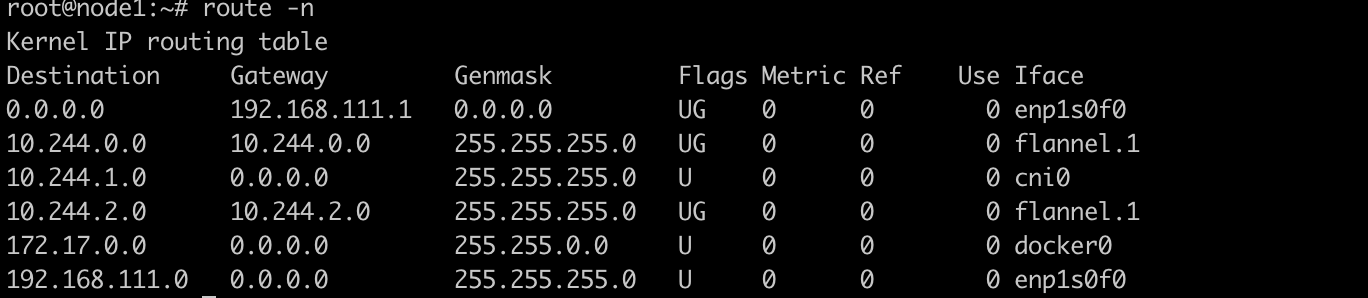
我们可以看到,25上,所有目标为10.244.0.0/24(本机容器)的包都会发往cni0网桥设备,本机通信,发往10.244.1.0/24和10.244.2.0/24(其他机器上的容器)的包都会被发往Flannel.1隧道设备。
Flannel.1为vxlan设备,当数据包来到flannel.1时,需要将数据包封装起来,因为是通过二层协议寻址,就需要目标ip地址对应的mac地址。此时,flannel.1不会发送arp请求去容器的mac地址,而是由Linux kernel将一个“L3 Miss”事件请求发送的用户空间的flanned程序。Flanned程序收到内核的请求事件之后,从etcd查找能够匹配该地址的子网的flannel.1设备的mac地址,即目标pod所在host中flannel.1设备的mac地址。Flannel在为Node节点分配ip网段时记录了所有的网段和mac等信息,并存储在ETCD中。[8]
同样的,在其他机器上,同机容器的包直接通过网桥转发,跨节点访问走隧道。这是26节点的路由表。
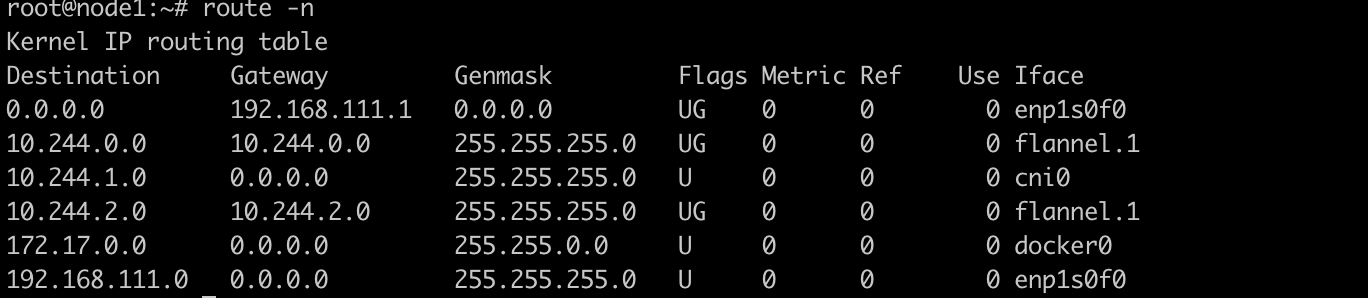
因为实际上采用的是二层网络,因此Flannel组网有很大的局限性。
- 子网的规模不会很大
- 跨节点访问过程中,因为要走隧道,需要重新封一个二层数据帧和解二层数据帧,因此性能有损失。
出于性能的考虑的话,Flannel并不是一个很好的选择,因此才有了其他的网络通信方案。
引用
- [1] guotianqing, linux中的网络命名空间的使用, CSDN
- [2] 猿大白, Linux 虚拟网络设备详解之 Bridge 网桥, 猿大白@公众号「Linux云计算网络」
- [3] public0821, Linux虚拟网络设备之bridge(桥), Segmentfault
- [4]工业通信发烧友, 二层网络结构和三层网络结构的对比, 知乎
- [5] luuJa_IQ, L2\L3层网络区别, CSDN
- [6] -零, 网络二层,三层的区别和寻址过程, 博客园
- [7] draveness.me, 为什么集群需要 Overlay 网络, draveness.me
- [8] 金色旭光, k8s网络之Flannel网络, 金色旭光
相关评论