
最近在做一个Kubernetes上的任务调度系统,做着做着遇到了一些有趣的问题,在这里总结一下。
在做系统设计的时候,对于我这样的分布式体系的初学者,一般都是从传统的单例开始去思考业务流程,进而设计系统的组件与功能。而分布式系统的一致性保证是一个一开始不会注意到,但是就像你玩吃鸡搜楼时,突然出现的那把喷子一样,一击要命。
先从一个简单的流程开始
我们要设计一个任务的调度系统,那么首先得明确任务的生命周期有哪几个阶段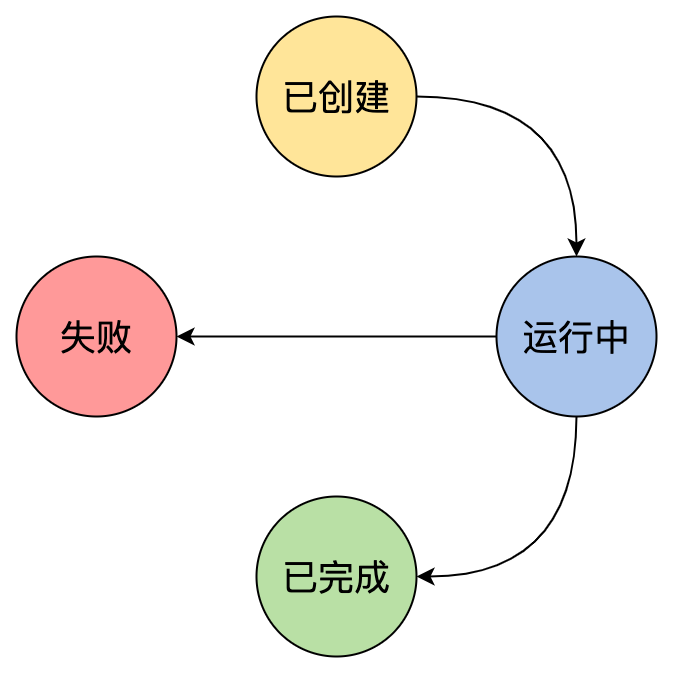
这是一个简单的四元状态,任务从创建开始,有完成和失败这两个终点。那么我们首先应该有一个数据库来记录这些状态,有个后端来读写。当然,并不是数据库有了一条记录,任务就跑完了,我们得实际的让任务跑起来,所以还得有个执行引擎,这里就是Kubernetes。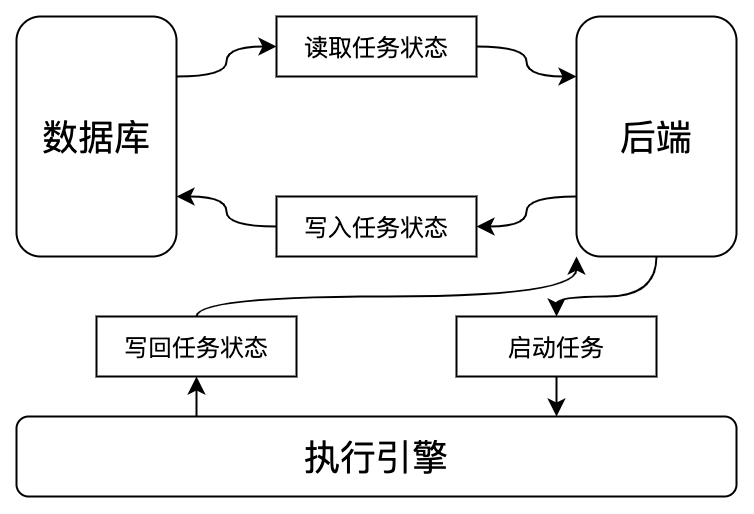
会出现状态不一致的情况吗?
在设计系统的时候,我们不能假设所有的组件,甚至包括网络环境是永远稳定的。事实上,大部分时间,包括网络这种基础环境可能都是不稳定的。当然,稳定性或者说可用性会有一个排序,可以先假设一些组件是高可用的,比如基础网络,不然这个系统设计就没法做了。
上面的系统设计里有一个问题,任务状态的写回是依靠容器内部的业务进程自己发起HTTP请求来告诉后端自己的任务执行情况的,是失败了还是成功了。但是,如果后端不可靠,给了一个错误的写回地址,或者容器内的业务进程实际完成了工作,但是没有执行写回操作,那么业务的状态就会一直保持为运行中,这与实际的负载情况是不一致的。
那么有没有什么办法可以避免这个问题呢?如果是在Kubernetes里,那么其实可以依靠监控容器的状态来确定任务的状态。在Kubernetes里,Pod可以有五个Status Phase,分别是Pending,Running,Succeeded,Failed,Unknown。这里,如果容器进程正常退出的话,就是Succeeded,异常退出就是Failed。我们可以利用这一点,不去Catch各种异常情况,当任务Crash的时候,就让它直接Crash掉。依靠Kubernetes来告诉我们这个业务的真实状态,本质上是用一种可用性更高的组件替换了可用性低的组件,来提升整体的可用性。
还有什么问题没考虑到吗?
我们到现在为止都是在假设只有一个后端实例的前提下做的设计。提升系统可用性的一个手段是多副本,那么如果实例数变多,会有什么问题呢?我们看一下改为多副本后的架构。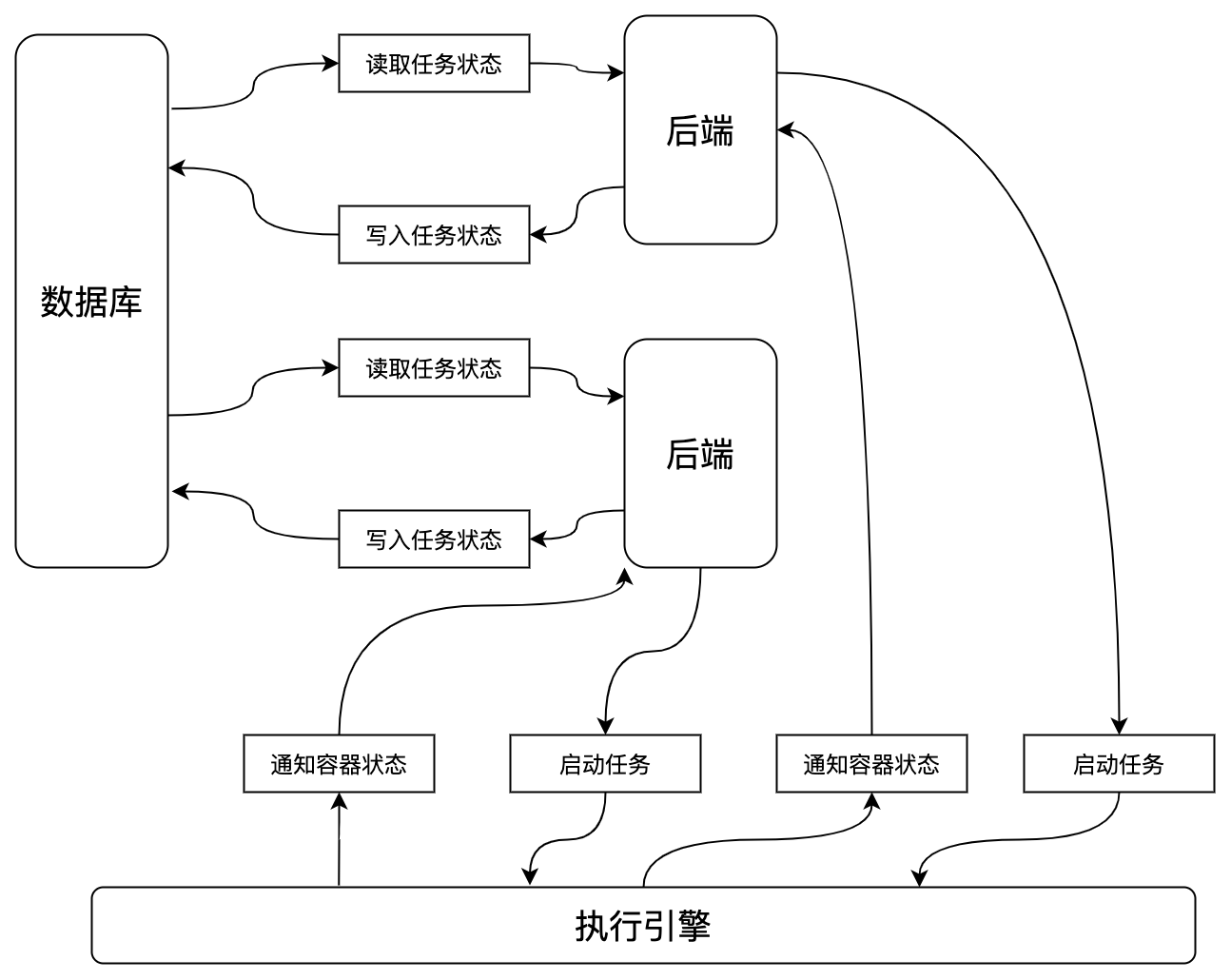
发现问题了吗?如果容器完成之后,Kubernetes会给每一个后端都通知一次这个Pod状态变成Succeeded或者Fail的事件,那么每个后端都会写一次数据库。我们可以相信Kubernetes是高可用的,不会出错的,那么就可以假设,通知容器状态这里是完全同步且通知的状态都一致的。那这里最大的问题就是,可能会出现重复写数据库的情况,有多少后端一个任务就会写多少次数据库。当然,假设数据库的承载能力无限,那这里其实也没什么大问题。
我们考虑更复杂的情况
刚才的任务生命周期只有四种简单的状态。不过,执行任务是要消耗资源的,资源是有可能不足的,任务执行也是可能会失败的,甚至用户可能跑一半不想跑了,任务是会被取消的,失败和取消的任务是可能重试的。让我们看一个更完整的任务生命周期图。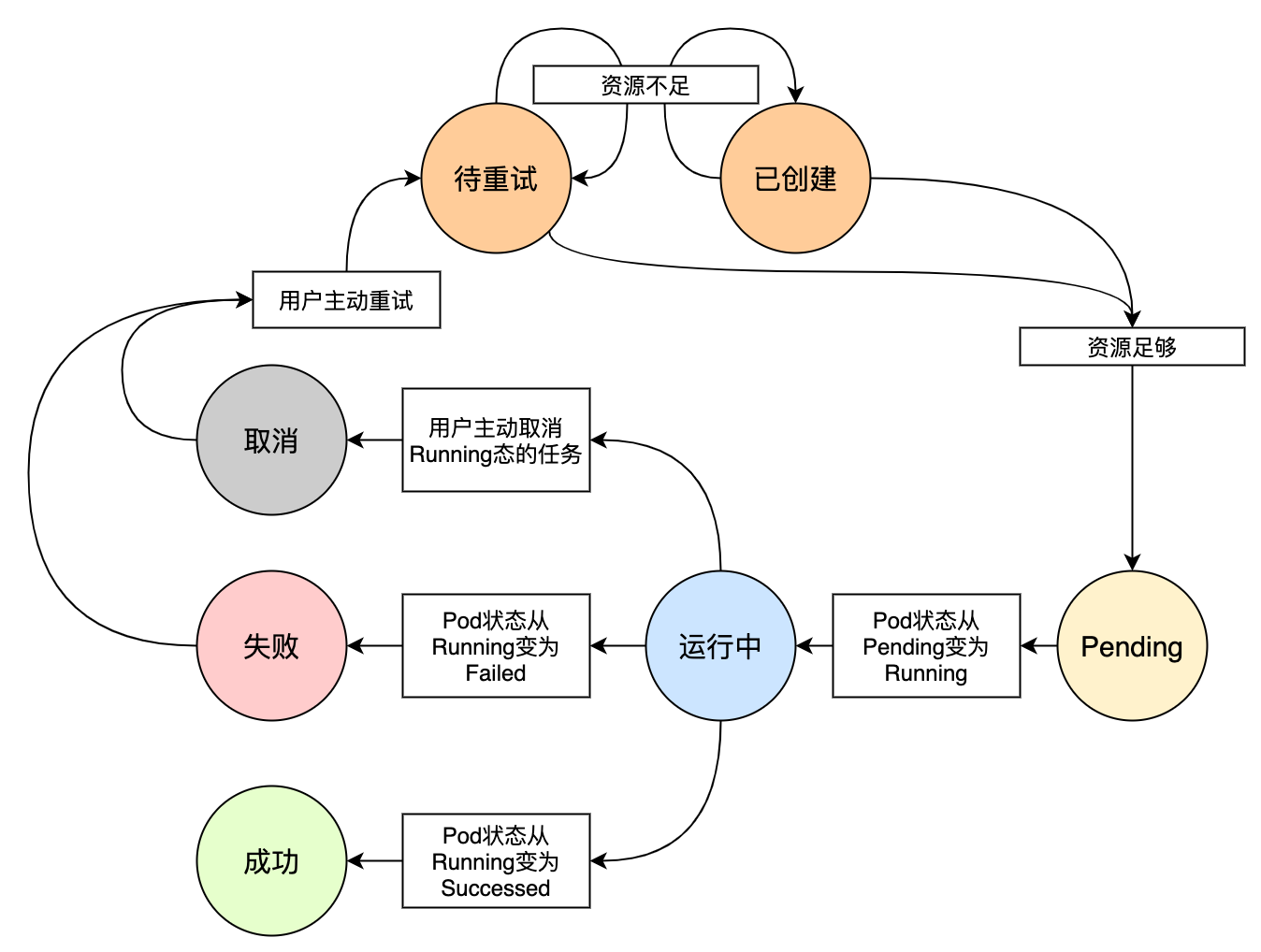
加入资源之后,我们又要考虑,资源的申请与释放。因此,刚才的架构图又有了新的内容。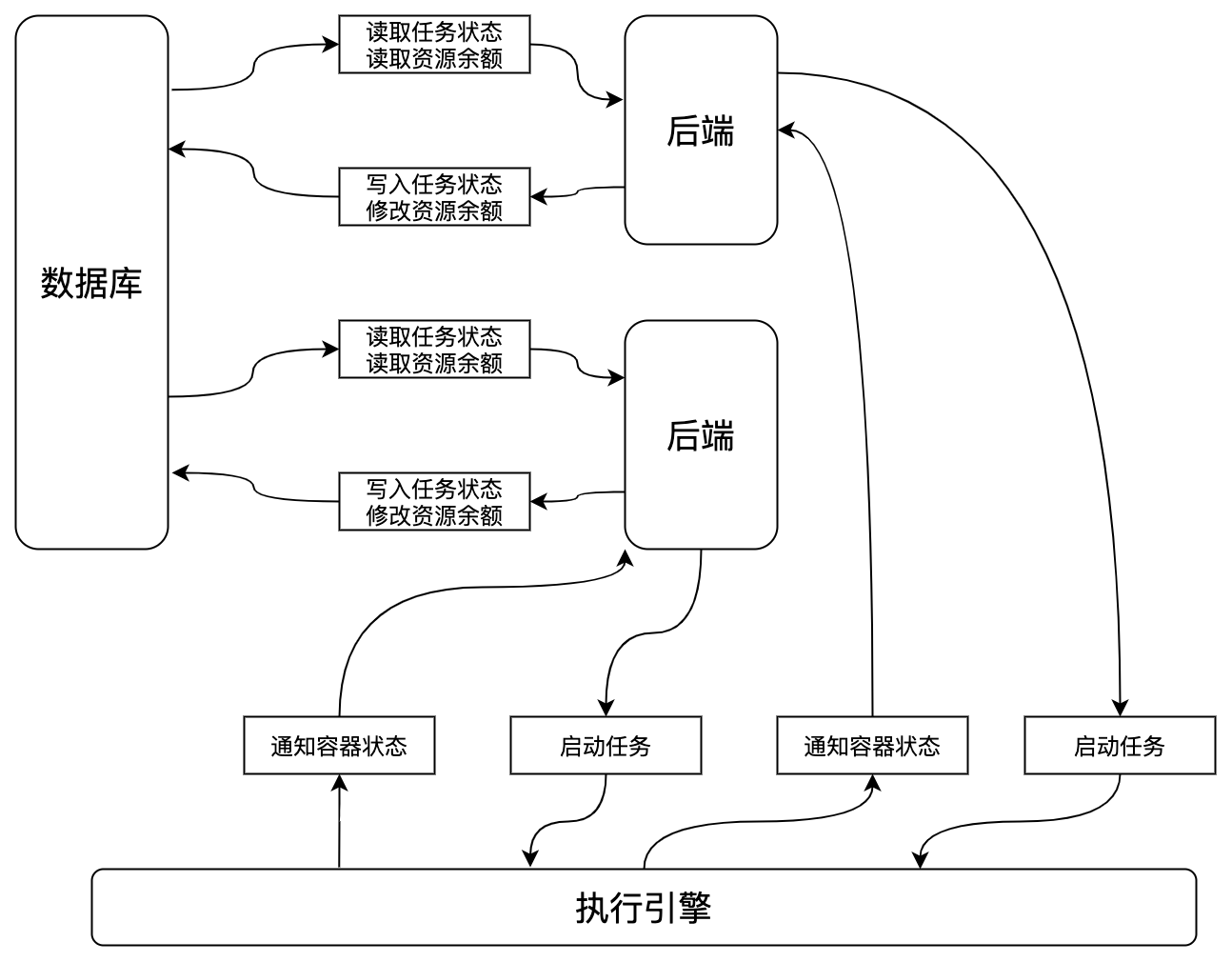
任务状态从已创建和待重试变成Pending态(启动容器,配置网络等,对应于Pod的Pending Phase)要占住资源,运行中变成成功、失败、取消时要释放资源。如果是单副本,一切都没有问题,但是,如果是多副本呢?我们仅看释放资源这里,现在每个后端不仅仅是往数据库里写一次任务状态了,他们还要增加资源的余量。于是,用户惊喜的发现,每跑完一次任务,可用剩余资源都增加了!(这倒是可以鼓励用户多跑任务)。
除此之外,还有一个可能产生不一致的地方,就是,每个后端都是要先从数据库读取当前的剩余,本地计算完新的余额后,再写入数据库。如果这个读->改->写没有做成原子事务的话,那么甚至有可能,对于有x个后端的系统,假设每个后端预期是释放1单位资源,最后增加的资源总量是小于x的(乐观点看这倒是让资源增加的没那么多)。
小小的总结一下
实际上,在资源的申请阶段也会有不一致问题。分布式系统中我们都知道可能有不一致的问题,但是有没有什么办法帮助我们快速诊断一个系统中有没有不一致问题呢?我个人的观点是这样的:
在系统中,出现了数据拷贝与分发环节,且分发的数据被后续组件有外部性的处理时,就可能会产生不一致的问题。
这里着重提一下,什么是外部性以及为什么要强调产生外部性。外部性就是这个组件基于这个数据,修改了系统内其他组件的状态,而如果这些分发的数据没有被有外部性的处理,比如只是存起来,在假设传输过程完全可靠的情况下,就不会有问题。那么可能有朋友会说,那传输不可靠呢?那这里其实就应该把网络设备也当成系统的组件来看待,网络设备接收了数据并传递给其他组件修改他们存储的状态,这就产生了外部性,自然,也会有不一致性问题。
一些解决办法
当然,可能产生不一致我们就要想办法去消除。有些可以简单想到的方案,比如说,既然是因为分发导致的,那么我就不分发好了,我只让一个后端来处理任务的资源申请和释放。这就是选主的思路,本质上是把后端又变成只有一个。另外的方式就是加锁,比如参考Kubernetes,做版本控制。但是加锁其实会引入很多性能的问题,所以如果能从系统设计的角度避免问题,我更倾向于设计更优雅的架构而不是用各种锁去强行保持强一致性。
相关评论